Publications
(†) denotes equal contribution
(*) denotes correspondance
denotes journal
denotes conference
denotes preprint
2026
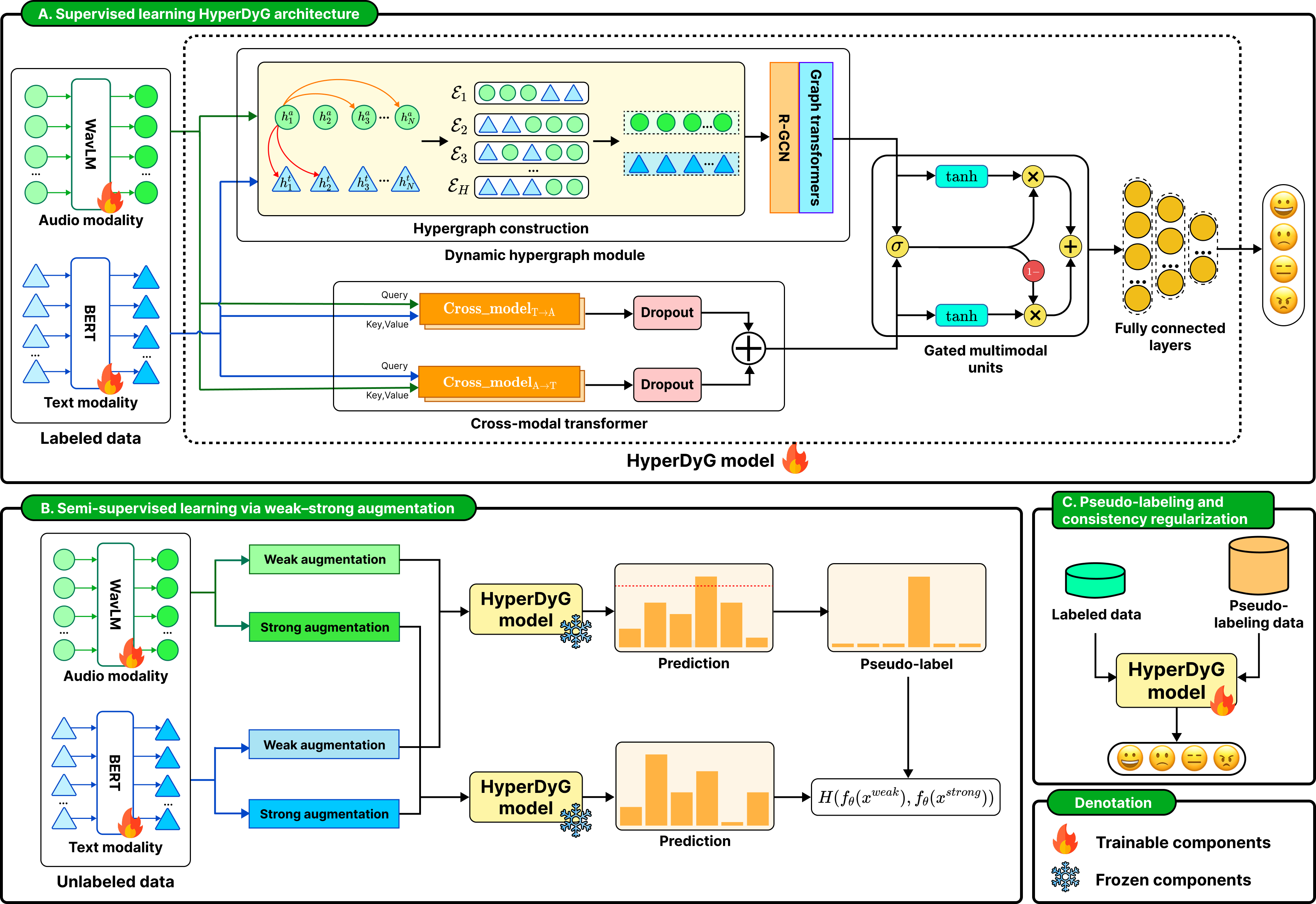
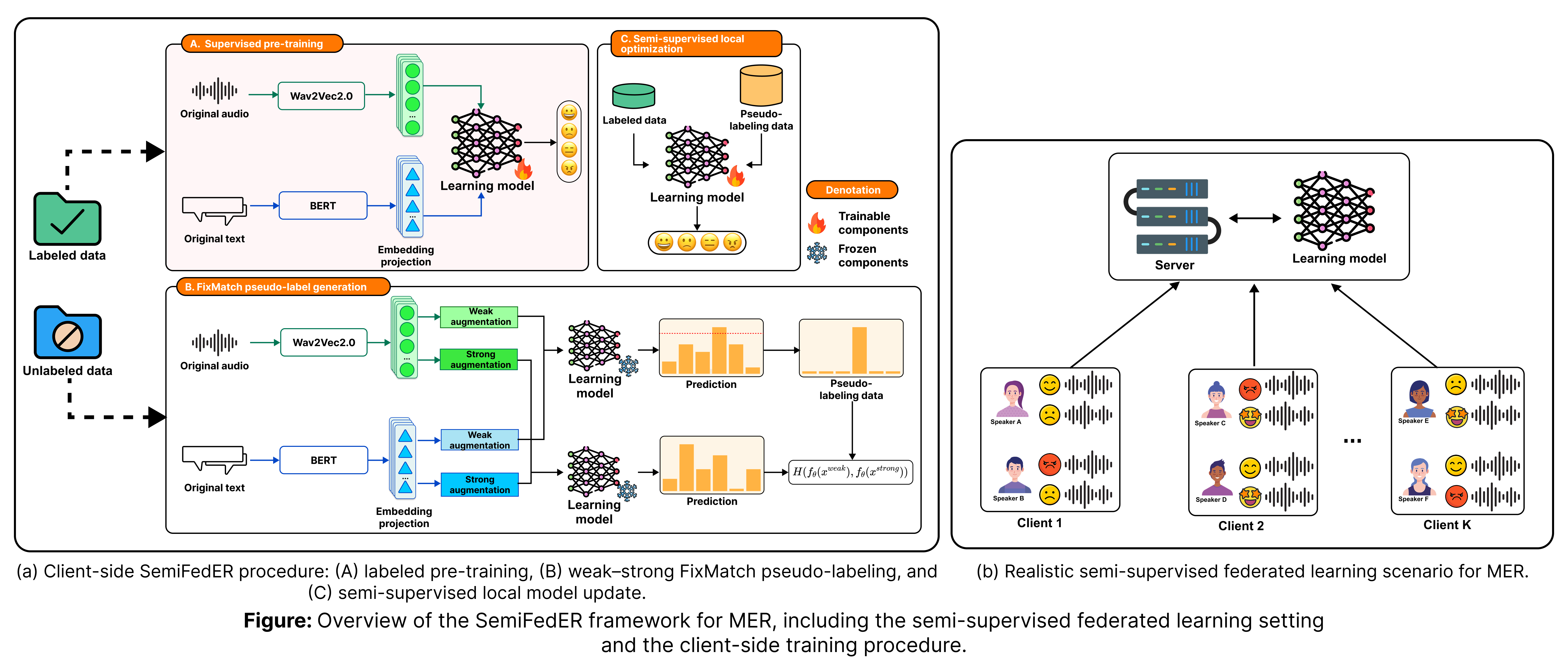
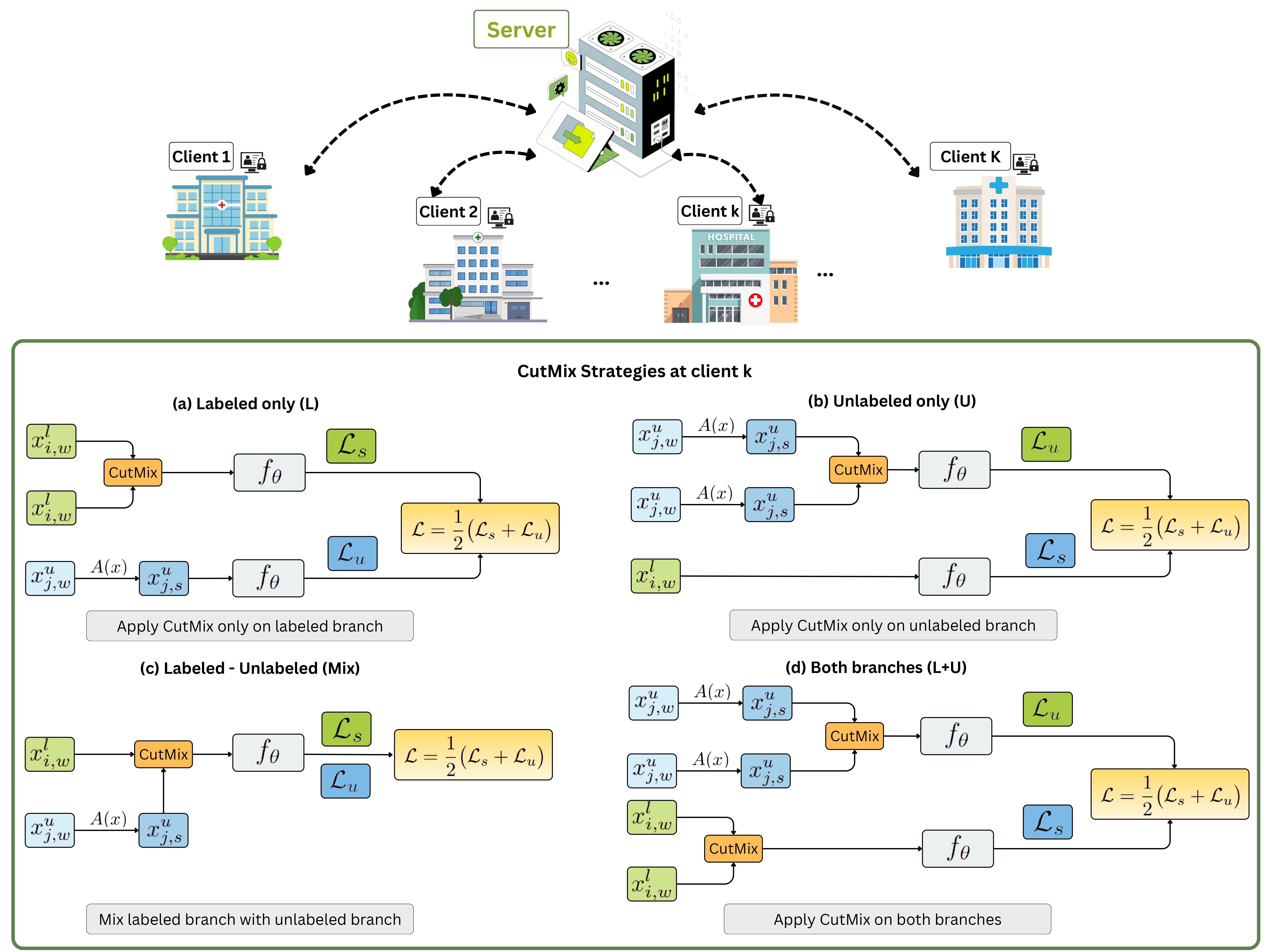
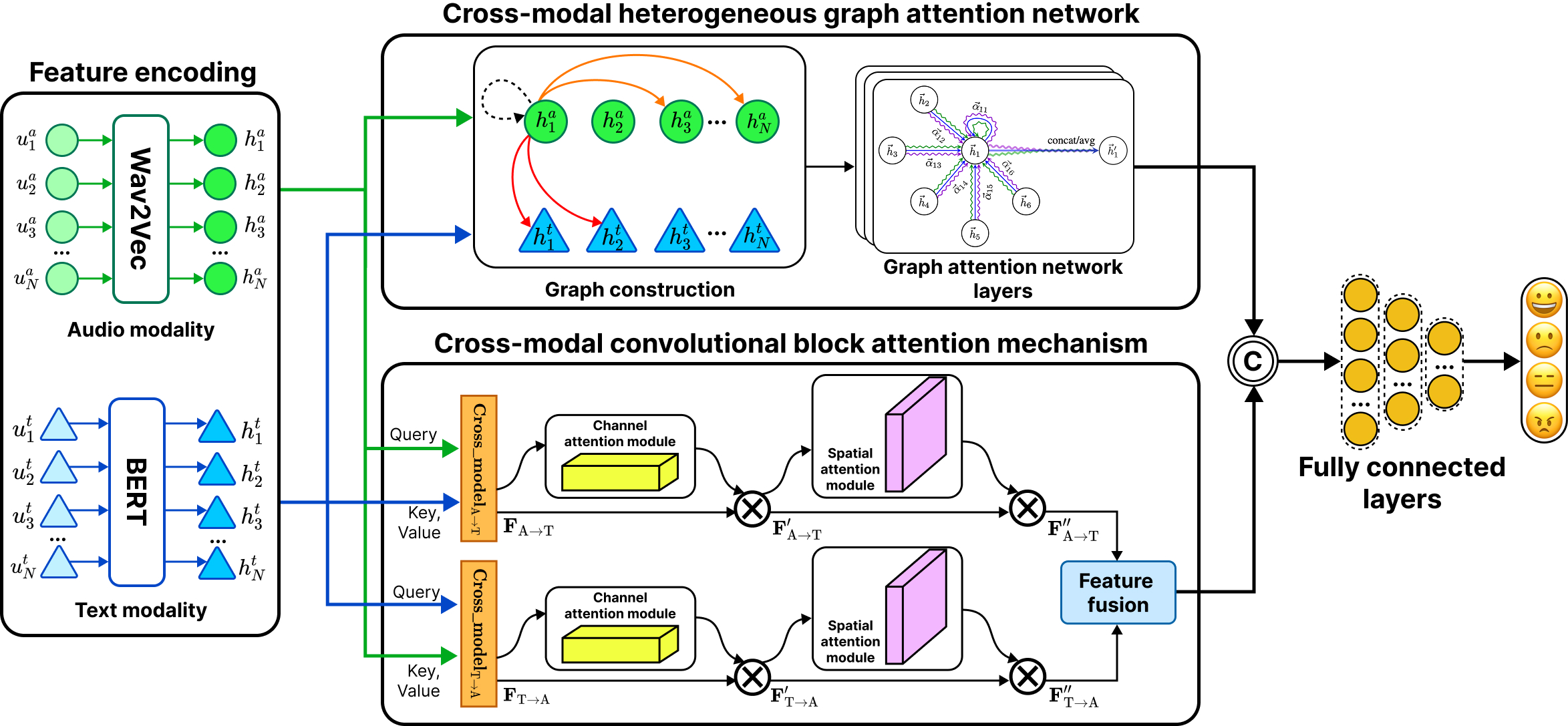
- HyperDyG: Hypergraph-Driven Dynamic Fusion for Semi-Supervised Multimodal Emotion RecognitionEAI Endorsed Transactions on Industrial Networks and Intelligent Systems Journal, Feb 2026
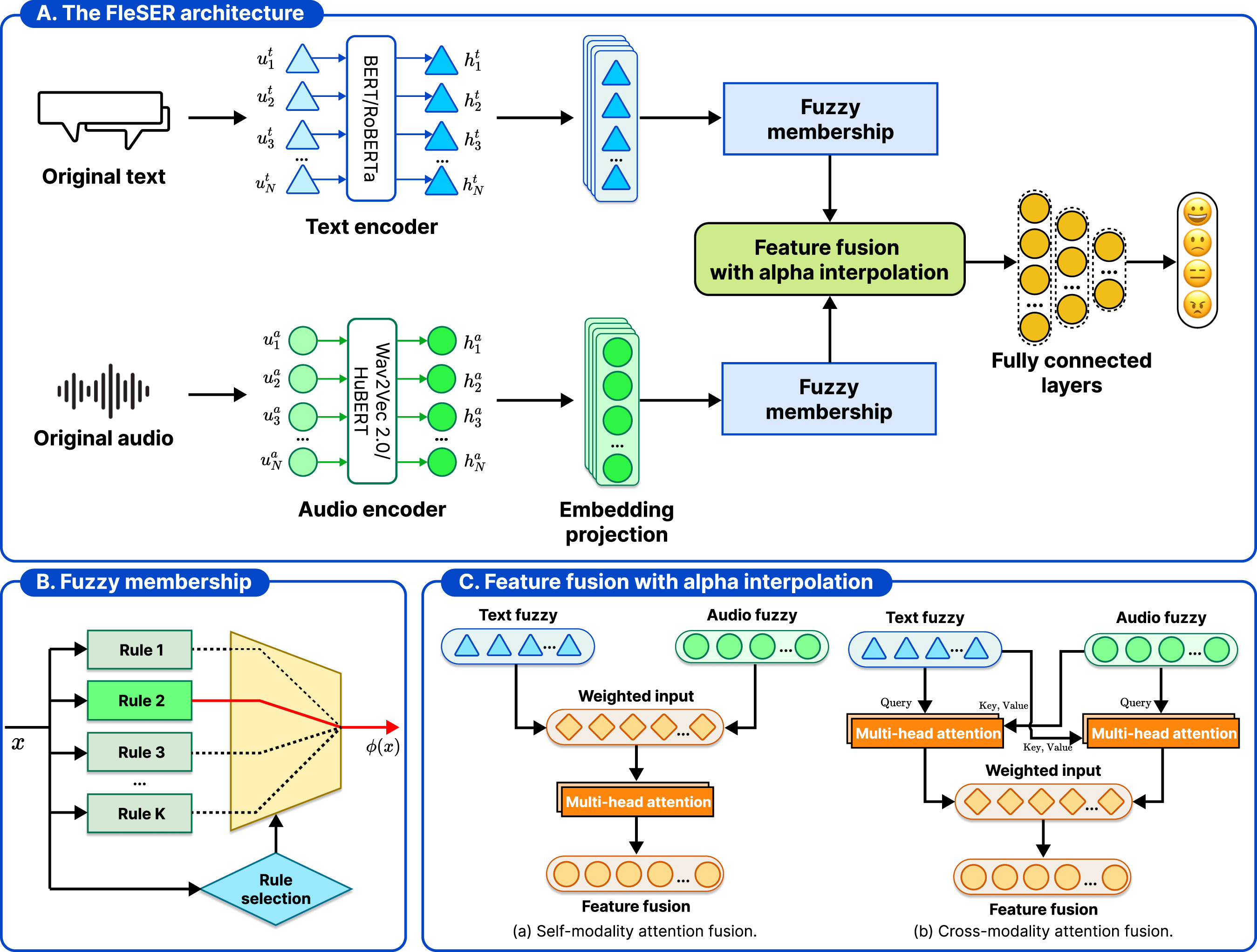
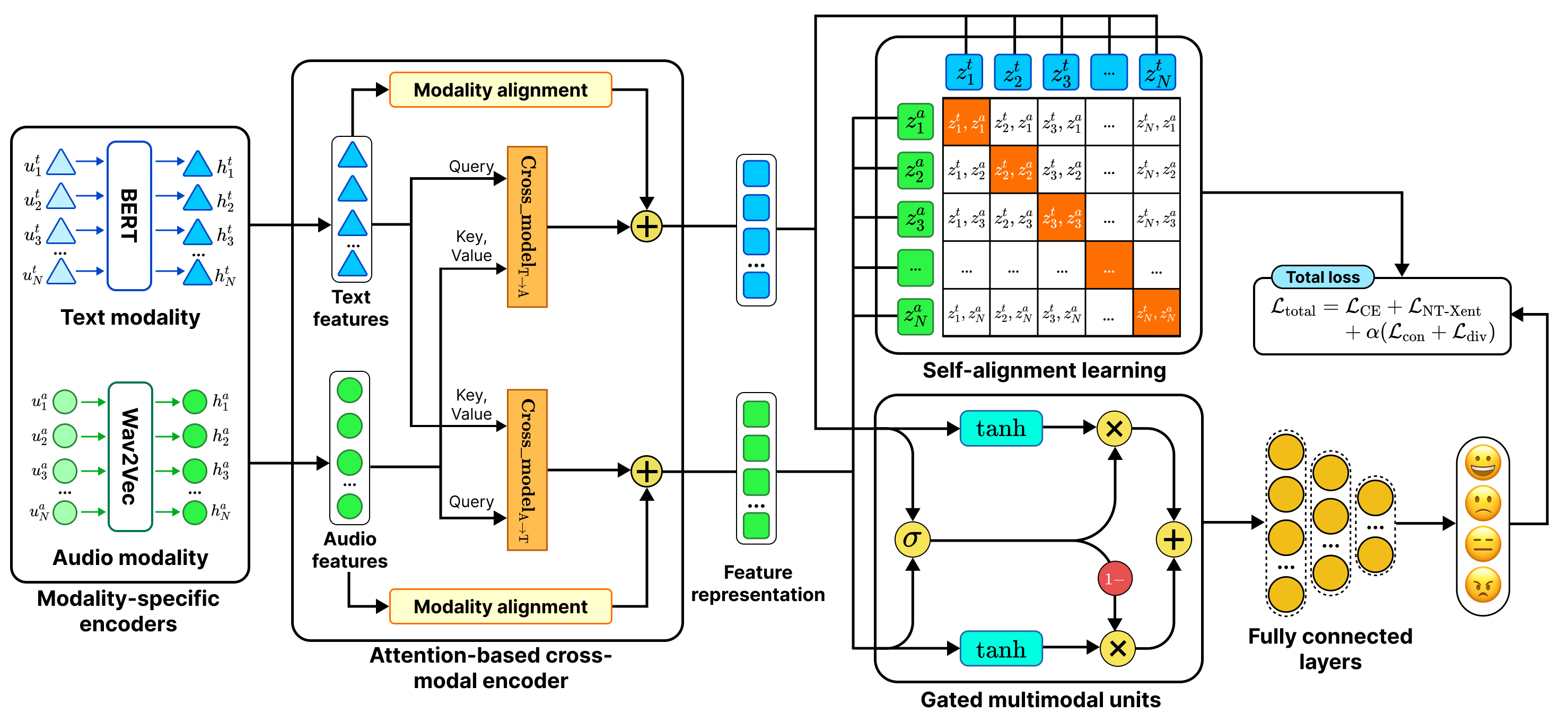
- Enhancing multimodal emotion recognition with dynamic fuzzy membership and attention fusionEngineering Applications of Artificial Intelligence, Feb 2026
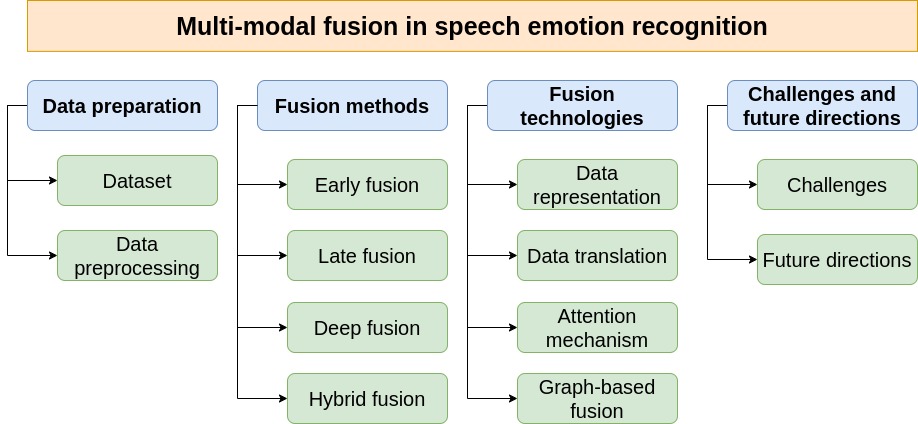
- Multimodal fusion in speech emotion recognition: A comprehensive review of methods and technologiesEngineering Applications of Artificial Intelligence, Jan 2026
2025
- YOLOv5-Powered Smart Parking System with IoT-Based Real-Time Slot MonitoringIn Proceedings of the 2025 RIVF International Conference on Computing and Communication Technologies (RIVF), Jan 2025
- In Proceedings of the 2025 Asia-Pacific Network Operations and Management Symposium (APNOMS), Sep 2025
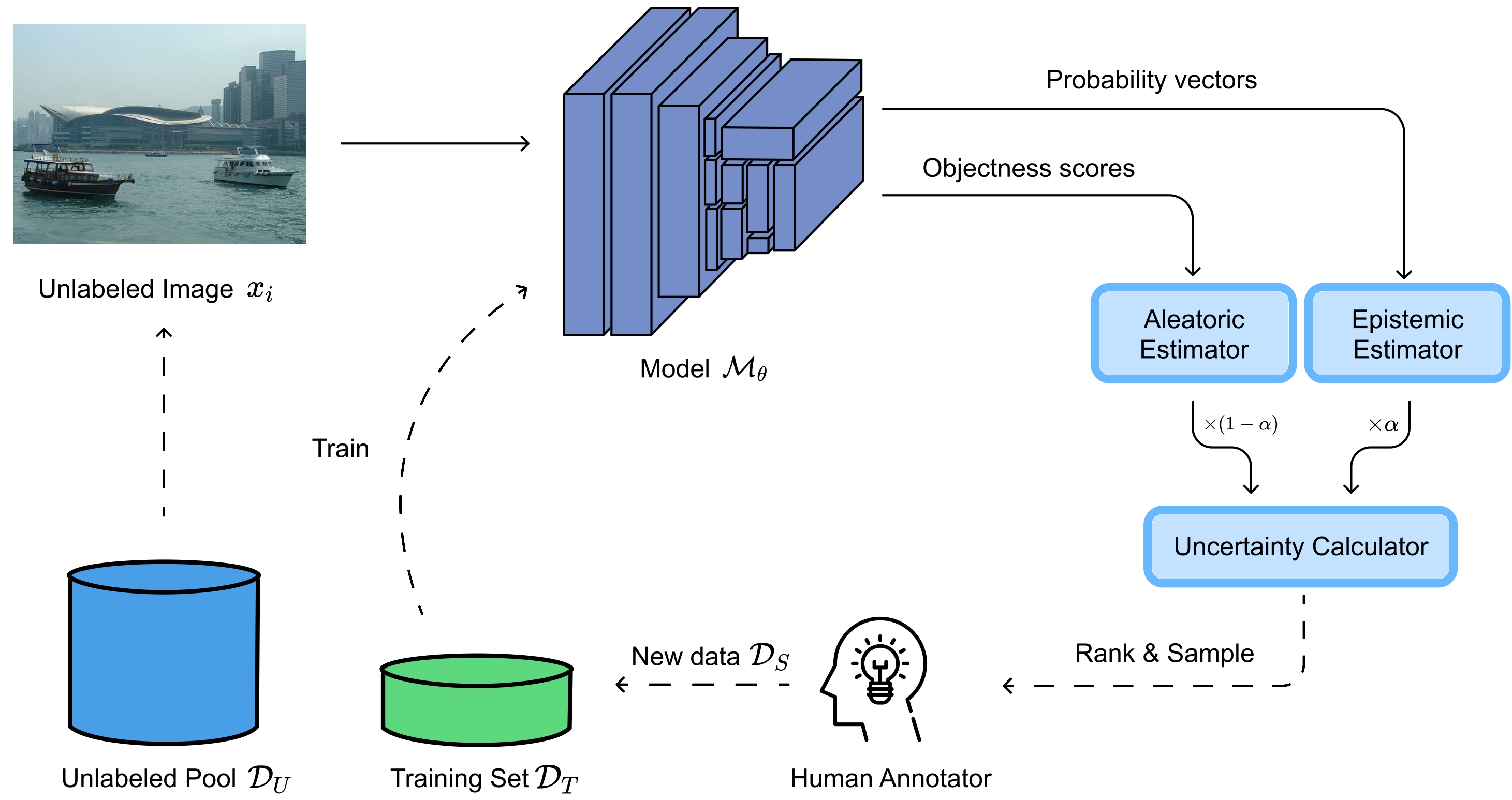
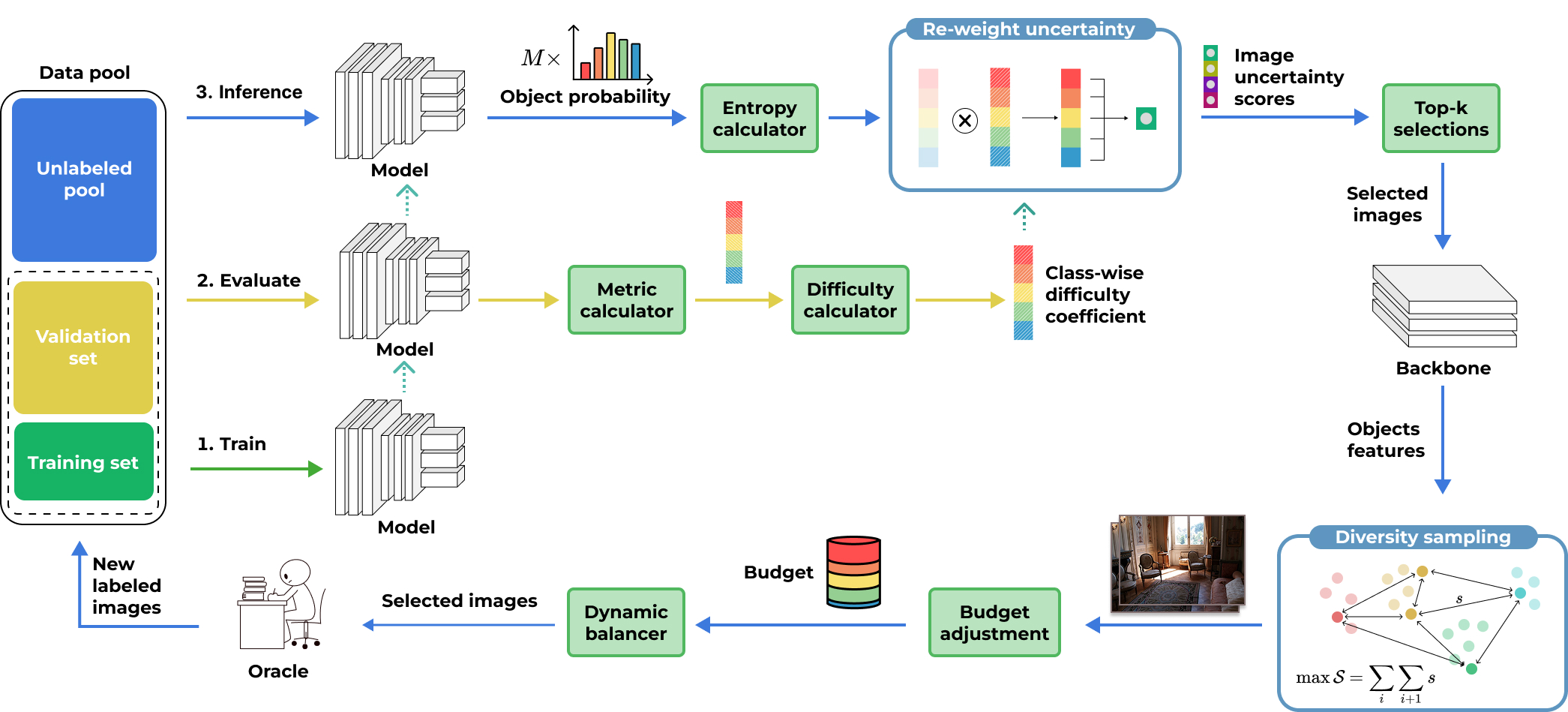
- ALMUS: Enhancing Active Learning for Object Detection with Metric-Based Uncertainty SamplingIn Proceedings of the 2025 Asia-Pacific Network Operations and Management Symposium (APNOMS), Sep 2025
- YOLO-Powered Traffic Sign Detection and OpenStreetMap Integration for Intelligent NavigationIn Proceedings of the 2025 Asia-Pacific Network Operations and Management Symposium (APNOMS), Sep 2025


2024
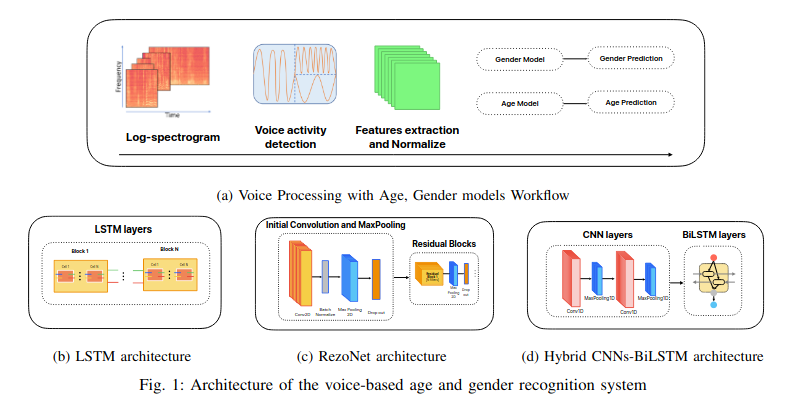
- Voice-Based Age and Gender Recognition: A Comparative Study of LSTM, RezoNet and Hybrid CNNs-BiLSTM ArchitectureIn Proceedings of the 2024 15th International Conference on Information and Communication Technology Convergence (ICTC), Sep 2024