Publications
(†) denotes equal contribution
(*) denotes correspondence
denotes journal
denotes conference
denotes preprint
2026
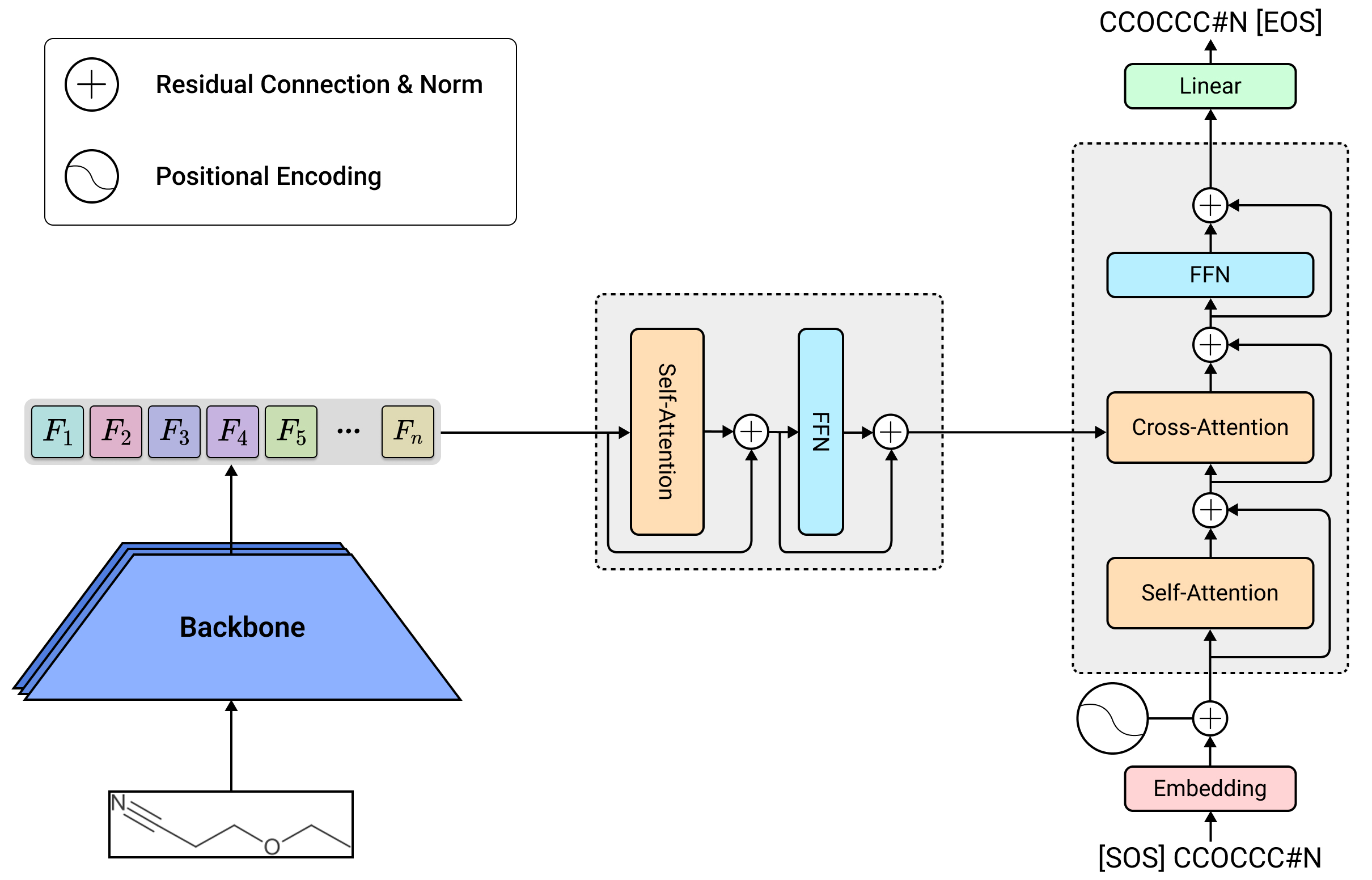
- Swin Transformer V2 for Optical Chemical Structure Recognition: Comparison with Convolutional Neural Networks and Swin Transformer VariantsThanh Trung Nguyen , Nhut Minh Nguyen, Duc Tai Phan, Quang Nhan Hoang , Tri Minh Pham, and Duc Ngoc Minh DangIn The 23rd International Conference on Electrical Engineering/Electronics, Computer, Telecommunication, and Information Technology, 2026
Optical Chemical Structure Recognition (OCSR) is designed to transform images of chemical structures into formats that computers can process, facilitating the extraction of molecular data from scientific publications on a large scale. Although modern deep learning methods have shown encouraging results, the impact of different visual backbone designs on understanding molecular structures has not been thoroughly investigated. This research compares various visual backbones for OCSR using an encoder-decoder architecture. The results show that while Convolutional Neural Network (CNN) architectures deliver excellent accuracy at the character level, Swin Transformer V2 generates more accurate molecular structures, as evidenced by superior Tanimoto similarity metrics. Moreover, even though Swin Transformer V2 has similar computational demands as the original Swin Transformer (V1), it exhibits enhanced training reliability and better capability for structural modeling, underscoring its effectiveness as a dependable visual backbone for OCSR applications.
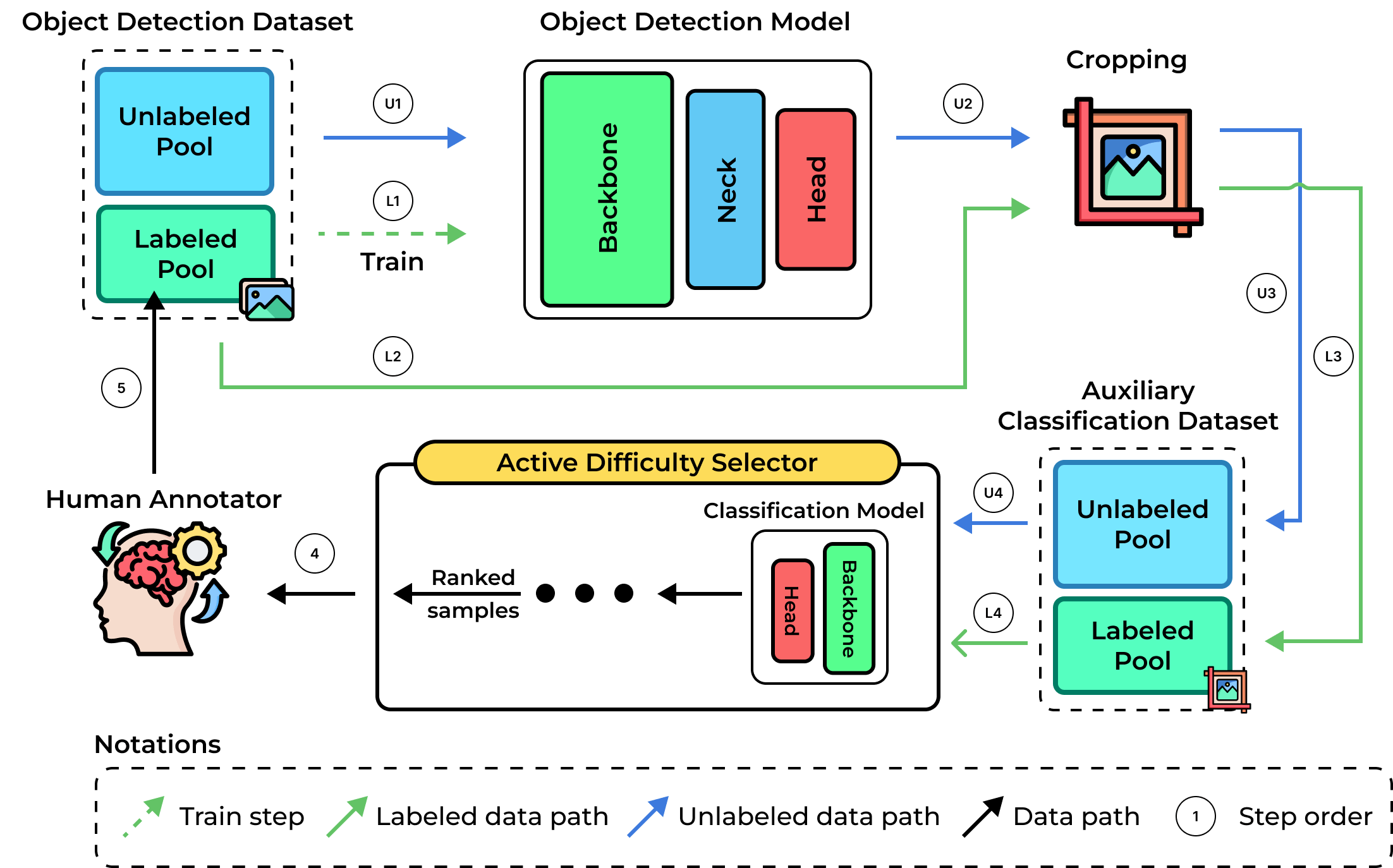
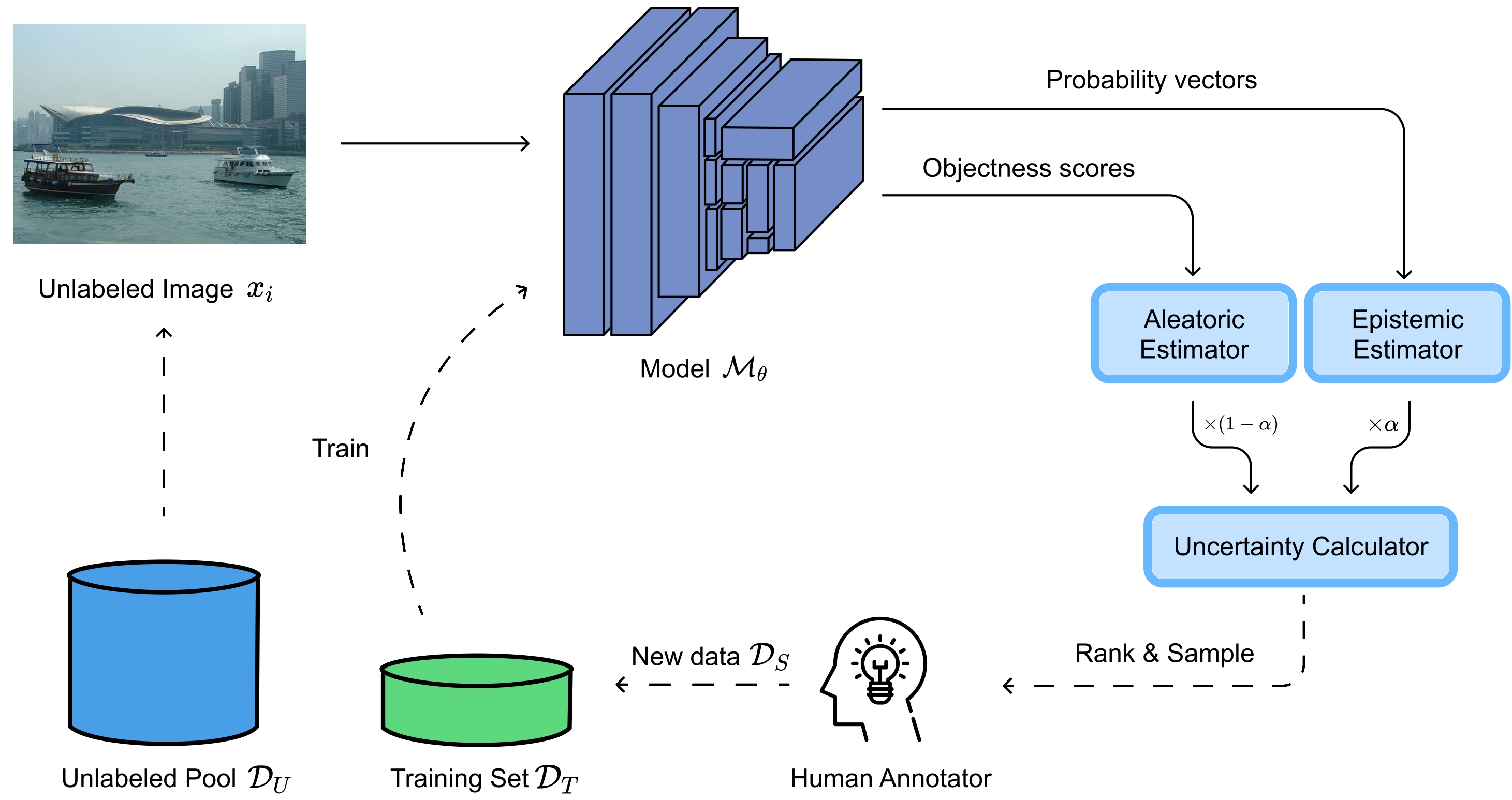
@inproceedings{Nguyen2025Ecti-Con, bibtex_show = true, author = {Nguyen, Thanh Trung and Nguyen, Nhut Minh and Phan, Duc Tai and Hoang, Quang Nhan and Pham, Tri Minh and Dang, Duc Ngoc Minh}, title = {Swin Transformer V2 for Optical Chemical Structure Recognition: Comparison with Convolutional Neural Networks and Swin Transformer Variants}, booktitle = {The 23rd International Conference on Electrical Engineering/Electronics, Computer, Telecommunication, and Information Technology}, address = {Chonburi, Thailand}, volume = {1}, pages = {299--304}, year = {2026}, doi = {10.1109/ECTI-CON68836.2026.11608590}, } - From object difficulty to image scoring: A strategy for active learning in object detectionDuc Tai Phan , Nhut Minh Nguyen , Khang Phuc Nguyen, Phuong-Nam Tran, Nhat Truong Pham, Linh Le, Choong Seon Hong, and Duc Ngoc Minh DangKnowledge-Based Systems, Apr 2026
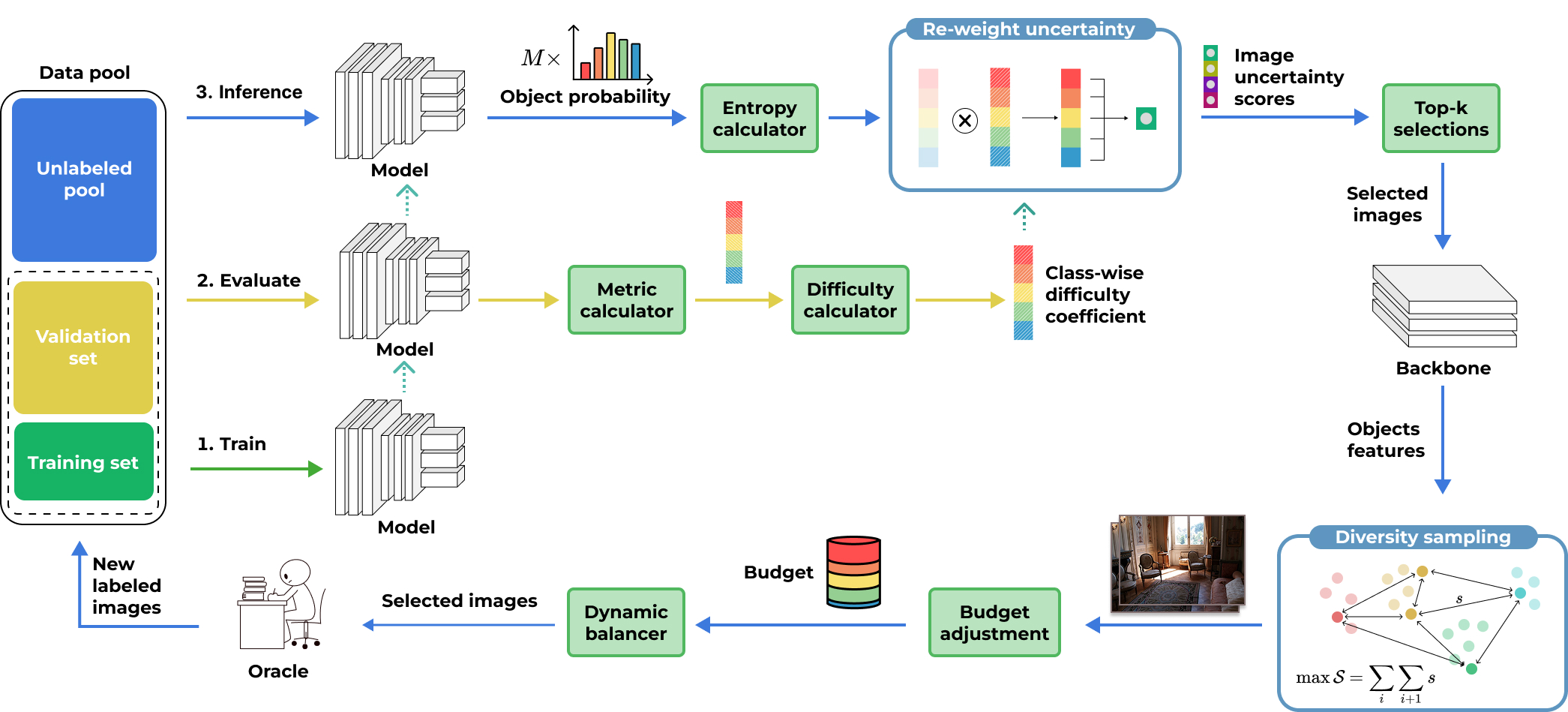
Object detection (OD) faces the costly hurdle of large-scale dataset annotation. Active Learning (AL) is a promising solution that selects the most beneficial samples for annotation. Applying AL to OD is challenging, as it requires addressing uncertainties in both classifying and localizing objects while combining object-level information into a single image-level decision. Current methods, like uncertainty sampling, often rely on output-level uncertainty or heuristic signal combinations. However, relying on static model outputs limits their ability to capture underlying feature-space instabilities. To address these limitations, we propose Feature Difficulty-based AL (FDAL), a novel framework that shifts the focus from output-level heuristics to active latent-space manipulation. By systematically interpolating unlabeled features toward class anchors, FDAL identifies prediction inconsistencies to reveal hidden traits unknown to the model. This anchor-guided interpolation unifies classification and localization uncertainties, capturing latent instabilities that traditional paradigms miss. Experiments on four OD benchmarks demonstrate that FDAL achieves state-of-the-art (SOTA) results, consistently improving detection accuracy while substantially reducing annotation costs. FDAL outperforms SOTA methods by 0.8% in detection accuracy on Pattern analysis, statistical modelling, and computational learning (PASCAL) Visual Object Classes (PASCAL VOC), 1.99% on Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI), 1.68% on Cityscapes, and 0.27% on Microsoft Common Objects in Context (MS COCO). FDAL’s selection is highly efficient, taking 0.06 seconds per image on PASCAL VOC and up to 0.63 seconds per image on Cityscapes, enabling scalability to large unlabeled pools. FDAL offers a practical, efficient, and effective solution for advancing AL in OD.
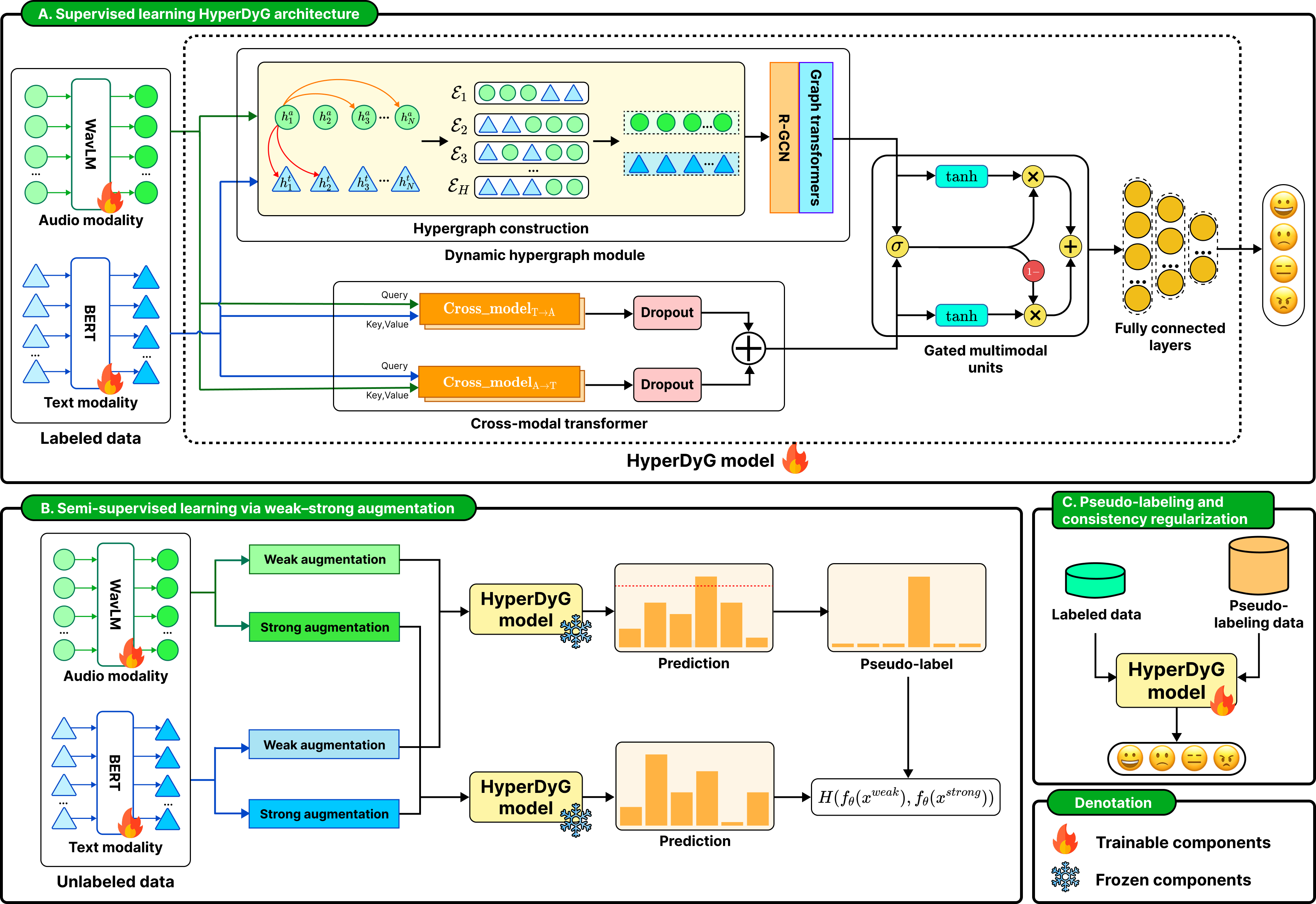
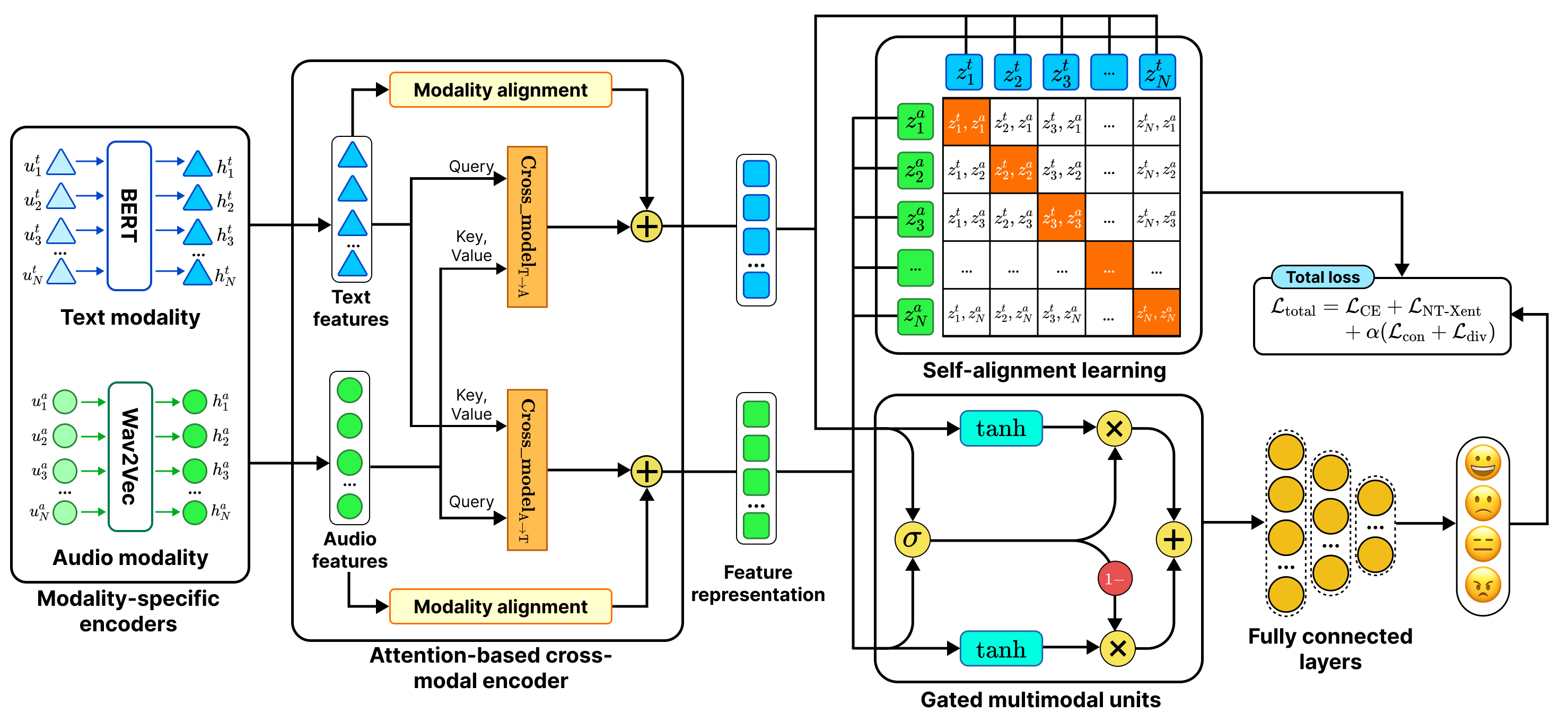
@article{PHAN2026115946, author = {Phan, Duc Tai and Nguyen, Nhut Minh and Nguyen, Khang Phuc and Tran, Phuong-Nam and Pham, Nhat Truong and Le, Linh and Hong, Choong Seon and Dang, Duc Ngoc Minh}, title = {From object difficulty to image scoring: A strategy for active learning in object detection}, journal = {Knowledge-Based Systems}, month = apr, year = {2026}, keywords = {Active learning, Object detection, Computer vision, Difficulty, Instability}, volume = {342}, pages = {115946}, issn = {0950-7051}, doi = {10.1016/j.knosys.2026.115946}, url = {https://www.sciencedirect.com/science/article/pii/S0950705126006726}, } - HyperDyG: Hypergraph-Driven Dynamic Fusion for Semi-Supervised Multimodal Emotion RecognitionNhut Minh Nguyen , Thu Thuy Le , Thanh Trung Nguyen , Hanh Ngoc Dang, Luu Phuong Vo, and Duc Ngoc Minh DangEAI Endorsed Transactions on Industrial Networks and Intelligent Systems Journal, Feb 2026
Speech emotion recognition (SER) is important in healthcare, education, human–computer interaction, and customer service. Multimodal emotion recognition (MER) integrates audio and textual modalities to achieve a comprehensive understanding of human affect, but still suffers from limited labeled data and complex cross-modal relations. To address these challenges, we propose HyperDyG, a dynamic hypergraph-driven MER framework. The HyperDyG leverages the strengths of dynamic hypergraph learning (DHL), cross-modal transformer (CMT), and an adaptive gated multimodal unit (GMU) for robust multimodal fusion. HyperDyG is further enhanced with a semi-supervised learning strategy that incorporates weak–strong augmentation, confidence-filtered pseudo-labeling, and consistency regularization to effectively exploit large-scale unlabeled data. The HyperDyG achieves state-of-the-art (SOTA) performance on the benchmark emotion dataset and maintains stable accuracy across varying unlabeled ratios. The findings of HyperDyG highlight the effectiveness and scalability of the proposed architecture in real-world low-label MER scenarios.
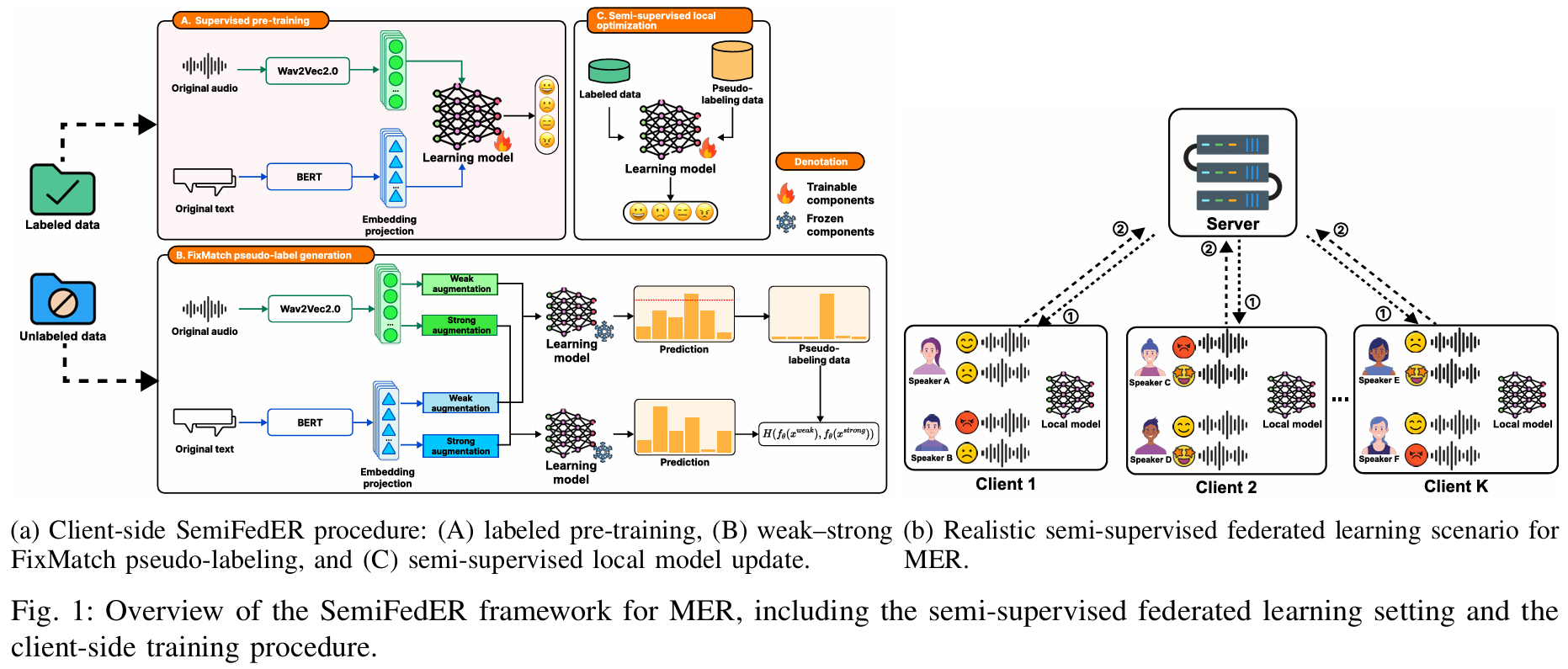
@article{nguyen2026HyperDyG, bibtex_show = true, title = {HyperDyG: Hypergraph-Driven Dynamic Fusion for Semi-Supervised Multimodal Emotion Recognition}, author = {Nguyen, Nhut Minh and Le, Thu Thuy and Nguyen, Thanh Trung and Dang, Hanh Ngoc and Vo, Luu Phuong and Dang, Duc Ngoc Minh}, journal = {EAI Endorsed Transactions on Industrial Networks and Intelligent Systems Journal}, volume = {13}, year = {2026}, month = feb, doi = {10.4108/eetinis.131.10903}, } - SemiFedER: Semi-supervised Federated Averaging for Multimodal Emotion RecognitionNhut Minh Nguyen , Thu Thuy Le , Thanh Trung Nguyen, and Duc Ngoc Minh DangIn Proceedings of the 7th International Conference on Machine Learning and Human-Computer Interaction (MLHMI 2026), Mar 2026To appear
Multimodal Emotion Recognition (MER) is a powerful approach for human–computer interaction, leveraging complementary cues across multiple modalities to infer human affect. MER has broad real-world potential in applications such as healthcare monitoring and affect-aware virtual assistants. However, practical deployments face two major challenges: large-scale data is often unlabeled due to the high cost of emotion annotation, and speech signals and transcripts are privacy-sensitive, limiting centralized data collection and training. To address these limitations, we propose SemiFedER, a semi-supervised federated learning framework for MER. SemiFedER performs client-side training in two stages, including supervised pre-training on labeled samples and semi-supervised learning that exploits unlabeled data via confidence-based pseudo-labeling and weak-strong consistency regularization. The server aggregates client updates using Federated Averaging (FedAvg) to learn a global model without sharing raw data. We deploy the representative centralized MER backbones within SemiFedER to assess their effectiveness in this practical setting. Extensive experiments on the MELD dataset under speaker-disjoint non-IID federated splits demonstrate that SemiFedER provides stable performance across labeled ratios and client counts, and achieves competitive improvements in class-balanced evaluation compared to centralized baselines.
@inproceedings{Nguyen2026SemiFedER, bibtex_show = true, title = {SemiFedER: Semi-supervised Federated Averaging for Multimodal Emotion Recognition}, author = {Nguyen, Nhut Minh and Le, Thu Thuy and Nguyen, Thanh Trung and Dang, Duc Ngoc Minh}, booktitle = {Proceedings of the 7th International Conference on Machine Learning and Human-Computer Interaction (MLHMI 2026)}, year = {2026}, address = {Tokyo, Japan}, month = mar, note = {To appear} } - HemoGAT: Heterogeneous Multimodal Speech Emotion Recognition with Cross-Modal Transformer and Graph Attention NetworkNhut Minh Nguyen , Thanh Trung Nguyen , Tien-Dat Nguyen, and Duc Ngoc Minh DangAdvances in Electrical and Electronic Engineering, Jun 2026
Multimodal speech emotion recognition (SER) is a promising field, yet effectively fusing diverse information streams remains challenging. Addressing this requires architectures capable of modeling structural relationships across modalities with fine-grained, feature-level interactions. This paper proposes HemoGAT, a novel heterogeneous multimodal SER architecture that integrates a dual-stream architecture with two core modules: a heterogeneous multimodal graph attention network (HM-GAT) and a cross-modal transformer (CMT) to address this. The HM-GAT module captures complex structural and contextual dependencies using a heterogeneous graph constructed from deep embeddings. The CMT module enables precise cross-modal feature fusion through bidirectional cross-attention. This design effectively captures both high-level relationships and immediate cross-modal influences. HemoGAT achieves state-of-the-art (SOTA) performance on the IEMOCAP dataset and highly competitive results on the MELD dataset, demonstrating its superiority over existing methods. Extensive ablation studies were conducted to evaluate HemoGAT. We assessed the impact of the Top-K algorithm for heterogeneous graph construction and compared unimodal and multimodal fusion strategies. We also examined the contributions of the HM-GAT and CMT modules, analyzed the role of the graph attention network (GAT) in graph learning, and evaluated the effect of GAT layer depth on performance.
@article{nguyen2026HemoGAT, bibtex_show = true, title = {HemoGAT: Heterogeneous Multimodal Speech Emotion Recognition with Cross-Modal Transformer and Graph Attention Network}, author = {Nguyen, Nhut Minh and Nguyen, Thanh Trung and Nguyen, Tien-Dat and Dang, Duc Ngoc Minh}, journal = {Advances in Electrical and Electronic Engineering}, year = {2026}, month = jun, doi = {10.15598/aeee.v24i2.250415}, } - Enhancing multimodal emotion recognition with dynamic fuzzy membership and attention fusionNhut Minh Nguyen , Minh Trung Nguyen , Thanh Trung Nguyen, Phuong-Nam Tran, Nhat Truong Pham, Linh Le, Alice Othmani, Abdulmotaleb El Saddik, and Duc Ngoc Minh DangEngineering Applications of Artificial Intelligence, Feb 2026
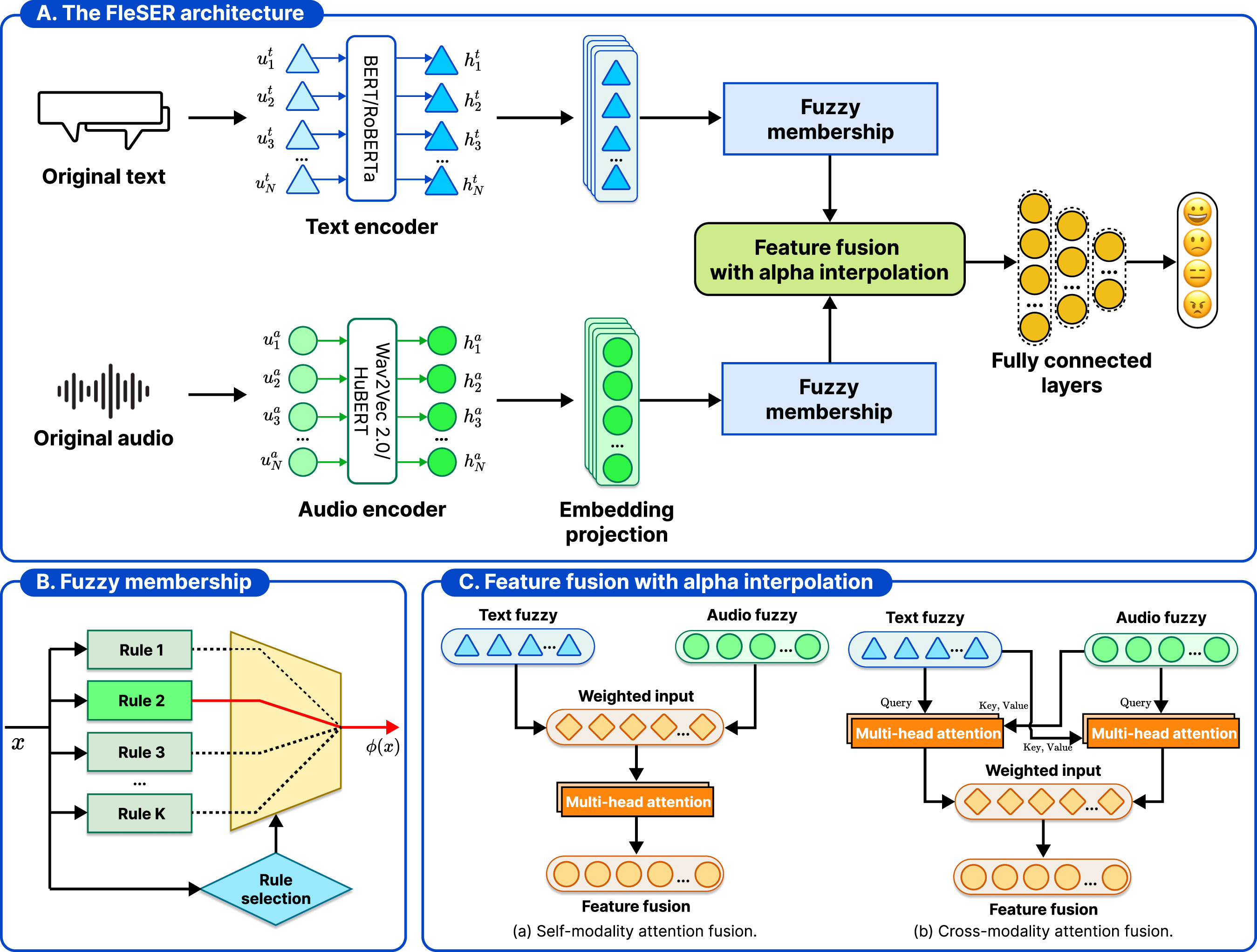
Multimodal learning has been shown to enhance classification outcomes in speech emotion recognition (SER). Despite this advantage, multimodal approaches in SER often face key challenges, including limited robustness to uncertainty, difficulty generalizing across diverse emotional contexts, and inefficiencies in integrating heterogeneous modalities. To overcome these constraints, we propose a multimodal emotion recognition architecture, named FleSER, which leverages dynamic fuzzy membership and attention-based fusion. Unlike most previous SER studies that apply fuzzy logic at the decision level, FleSER introduces a feature-level, rule-based dynamic fuzzy membership mechanism that adaptively refines modality representations prior to fusion. The FleSER architecture leverages audio and textual modalities, employing self-modality and cross-modality attention mechanisms with the α interpolation to capture complementary emotional cues. The α interpolation-based feature fusion mechanism adaptively emphasizes the more informative modality across varying contexts, ensuring robust multimodal integration. This comprehensive design enhances recognition accuracy. We evaluate FleSER on multiple benchmark datasets, surpassing previous state-of-the-art (SOTA) approaches and demonstrating superior effectiveness in emotion recognition. Ablation studies further validate the effectiveness of each key component, including unimodal and multimodal input effectiveness, fuzzy membership functions, fusion strategies, and the projection dimension, on the performance of the FleSER architecture.
@article{nguyen2026fleser, title = {Enhancing multimodal emotion recognition with dynamic fuzzy membership and attention fusion}, author = {Nguyen, Nhut Minh and Nguyen, Minh Trung and Nguyen, Thanh Trung and Tran, Phuong-Nam and Pham, Nhat Truong and Le, Linh and Othmani, Alice and Saddik, Abdulmotaleb El and Dang, Duc Ngoc Minh}, journal = {Engineering Applications of Artificial Intelligence}, year = {2026}, month = feb, doi = {10.1016/j.engappai.2025.113396}, } - Multimodal fusion in speech emotion recognition: A comprehensive review of methods and technologiesNhut Minh Nguyen , Thanh Trung Nguyen, Phuong-Nam Tran, Chee Peng Lim, Nhat Truong Pham, and Duc Ngoc Minh DangEngineering Applications of Artificial Intelligence, Jan 2026
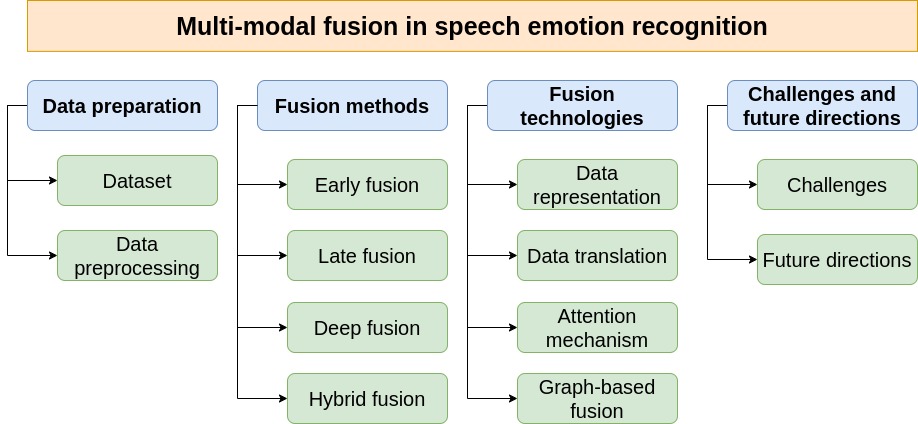
Speech emotion recognition (SER) plays a crucial role in human-computer interaction, enhancing numerous applications such as virtual assistants, healthcare monitoring, and customer support by identifying and interpreting emotions conveyed through spoken language. While single-modality SER systems demonstrate notable simplicity and computational efficiency, excelling in extracting critical features like vocal prosody and linguistic content, there is a pressing need to improve their performance in challenging conditions, such as noisy environments and the handling of ambiguous expressions or incomplete information. These challenges underscore the necessity of transitioning to multi-modal approaches, which integrate complementary data sources to achieve more robust and accurate emotion detection. With advancements in artificial intelligence, especially in neural networks and deep learning, many studies have employed advanced deep learning and feature fusion techniques to enhance SER performance. This review synthesizes comprehensive publications from 2020 to 2024, exploring prominent multi-modal fusion strategies, including early fusion, late fusion, deep fusion, and hybrid fusion methods, while also examining data representation, data translation, attention mechanisms, and graph-based fusion technologies. We assess the effectiveness of various fusion techniques across standard SER datasets, highlighting their performance in diverse tasks and addressing challenges related to data alignment, noise management, and computational demands. Additionally, we explore potential future directions for enhancing multi-modal SER systems, emphasizing scalability and adaptability in real-world applications. This survey aims to contribute to the advancement of multi-modal SER and to inform researchers about effective fusion strategies for developing more responsive and emotion-aware systems.
@article{nguyen2025MSER, bibtex_show = true, title = {Multimodal fusion in speech emotion recognition: A comprehensive review of methods and technologies}, author = {Nguyen, Nhut Minh and Nguyen, Thanh Trung and Tran, Phuong-Nam and Lim, Chee Peng and Pham, Nhat Truong and Dang, Duc Ngoc Minh}, journal = {Engineering Applications of Artificial Intelligence}, year = {2026}, month = jan, doi = {10.1016/j.engappai.2025.112624}, }
2025
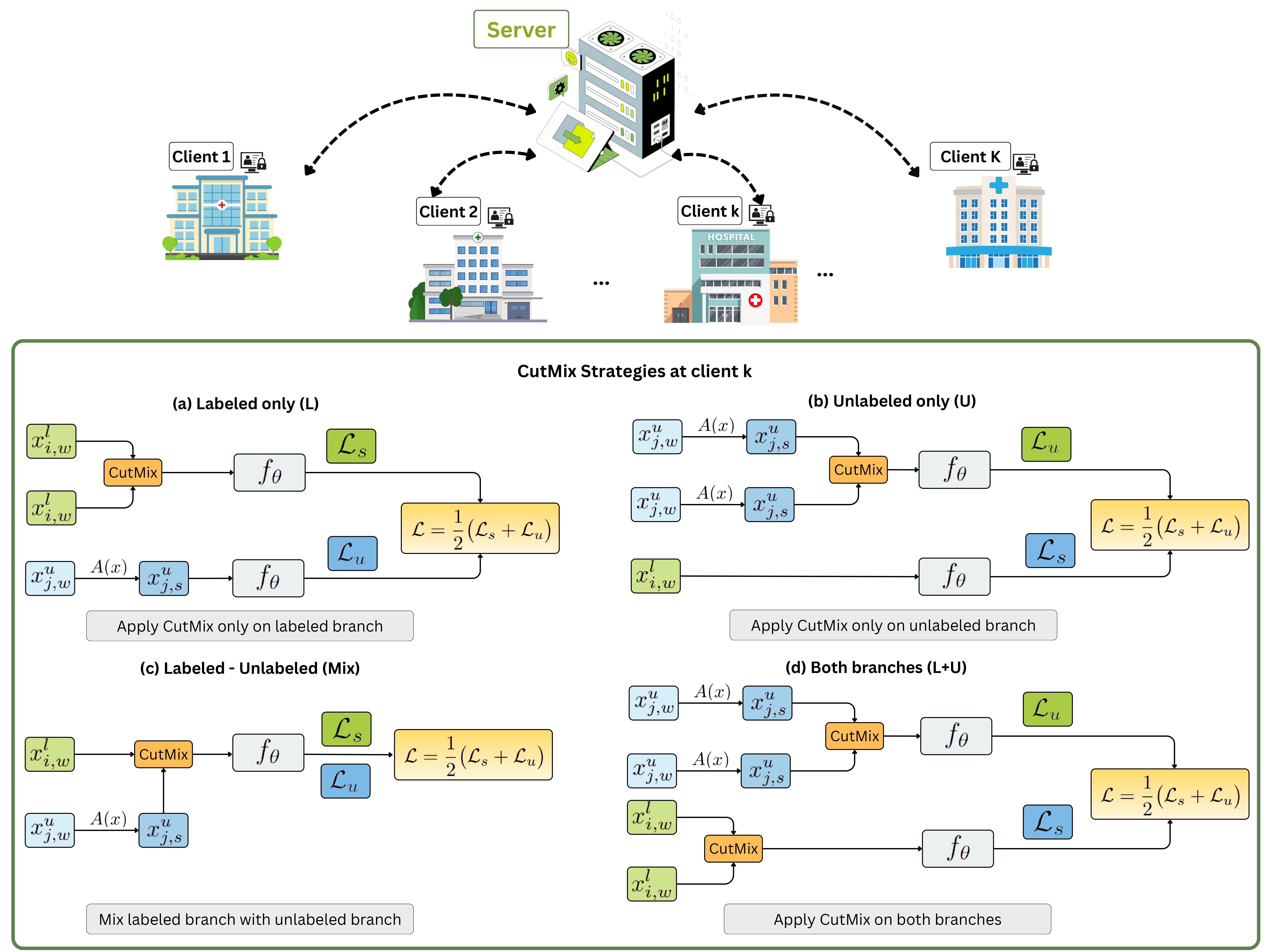
- Federated Semi-Supervised FixMatch: Enhancing CutMix for Medical Image SegmentationThu Thuy Le , Nhut Minh Nguyen, Nhat Truong Pham, Phuong-Nam Tran, Nguyen Doan Hieu Nguyen, Phuong Luu Vo, Balachandran Manavalan, and Duc Ngoc Minh DangIn 2025 IEEE International Conference on Big Data, Jan 2025
Previous studies on federated learning (FL) often assume that each client has access to fully labeled data. In reality, however, most hospitals and clinical facilities lack sufficient labeled data, as annotation is costly and requires highly skilled experts. The key challenge, therefore, is how to effectively train FL models when only a small portion of data at each client is labeled. Federated semi-supervised learning (FSSL) has emerged as a promising solution. From the perspective of big data, this challenge is further intensified by the large scale, heterogeneity, and non-IID nature of data distributions. These factors significantly affect training efficiency, making it crucial to fully leverage diverse unlabeled datasets while ensuring privacy and minimizing communication costs for large-scale FL deployment. In this study, we apply data augmentation in FSSL to make better use of unlabeled data together with the limited amount of labeled data. Specifically, we investigate the role of CutMix, a widely used patch-level augmentation technique, when combined with Federated FixMatch (FedFixMatch). We evaluate different strategies, including applying CutMix only to labeled data, only to unlabeled data, to both branches, or to mixed data, and examine their effects under varying annotation conditions and heterogeneous client distributions. Additionally, we examine the impact of CutMix on communication efficiency, convergence dynamics, and training stability within FedFixMatch. To the best of our knowledge, this work provides the first comprehensive benchmark of CutMix strategies in FSSL for medical image segmentation. Our results provide important guidance for developing efficient augmentation strategies that address the practical challenges of big data and FL.
@inproceedings{Le2025BigData, author = {Le, Thu Thuy and Nguyen, Nhut Minh and Pham, Nhat Truong and Tran, Phuong{-}Nam and Nguyen, Nguyen Doan Hieu and Vo, Phuong Luu and Manavalan, Balachandran and Dang, Duc Ngoc Minh}, title = {Federated Semi-Supervised FixMatch: Enhancing CutMix for Medical Image Segmentation}, booktitle = {2025 IEEE International Conference on Big Data}, year = {2025}, address = {Macau SAR, China}, bibtex_show = true, doi = {10.1109/BigData66926.2025.11402514}, } - YOLOv5-Powered Smart Parking System with IoT-Based Real-Time Slot MonitoringPhuong Lam Nguyen, Duc Tai Phan , Thanh Trung Nguyen , Nhut Minh Nguyen, and Duc Ngoc Minh DangIn Proceedings of the 2025 RIVF International Conference on Computing and Communication Technologies (RIVF), Jan 2025
Finding a parking space has become a daily struggle in an era of rapid urbanization and increasing car ownership, contributing to traffic congestion, lost time, and environmental stress. To transform urban parking management, this study presents a novel Smart Parking System (SPS) that seamlessly integrates deep learning and Internet of Things (IoT) technologies. Our SPS delivers a streamlined workflow, featuring real-time slot occupancy detection via a fine-tuned YOLOv5 model analyzing camera feeds, automated entry/exit handling triggered by IoT sensors, and a specialized License Plate Recognition (LPR) model. Additionally, it includes secure cloud-based data logging for effortless tracking and billing. The web dashboard provides real-time, color-coded visualizations of slot availability, supporting efficient parking management. Experimental evaluation demonstrates an accuracy of 90% in license plate recognition and over 99.5% in slot occupancy detection, highlighting the system’s reliability and practical applicability for smart city deployment.
@inproceedings{Nguyen2025Parking, bibtex_show = true, author = {Nguyen, Phuong Lam and Phan, Duc Tai and Nguyen, Thanh Trung and Nguyen, Nhut Minh and Dang, Duc Ngoc Minh}, booktitle = {Proceedings of the 2025 RIVF International Conference on Computing and Communication Technologies (RIVF)}, title = {YOLOv5-Powered Smart Parking System with IoT-Based Real-Time Slot Monitoring}, year = {2025}, pages = {693-698}, keywords = {YOLO;Analytical models;Smart cities;Automated parking;Real-time systems;Internet of Things;License plate recognition;Monitoring;Traffic congestion;Intelligent sensors;Smart Parking System;License Plate Recognition;Real-Time Slot Monitoring;YOLOv5;Optical Character Recognition;Computer Vision}, doi = {10.1109/RIVF68649.2025.11365041}, } - GloMER: Towards Robust Multimodal Emotion Recognition via Gated Fusion and Contrastive LearningNhut Minh Nguyen, Duc Tai Phan, and Duc Ngoc Minh DangIn Proceedings of the 17th International Conference on Management of Digital Ecosystem (MEDES 2025), Nov 2025To appear
@inproceedings{nguyen2025GloMER, bibtex_show = true, title = {GloMER: Towards Robust Multimodal Emotion Recognition via Gated Fusion and Contrastive Learning}, author = {Nguyen, Nhut Minh and Phan, Duc Tai and Dang, Duc Ngoc Minh}, booktitle = {Proceedings of the 17th International Conference on Management of Digital Ecosystem (MEDES 2025)}, year = {2025}, month = nov, address = {Ho Chi Minh City, Vietnam}, organization = {FPT University}, note = {To appear} } - DAAL: Dual Ambiguity in Active Learning for Object Detection with YOLOEDuc Tai Phan , Nhut Minh Nguyen, and Duc Ngoc Minh DangIn Proceedings of the 17th International Conference on Management of Digital Ecosystem (MEDES 2025), Nov 2025To appear
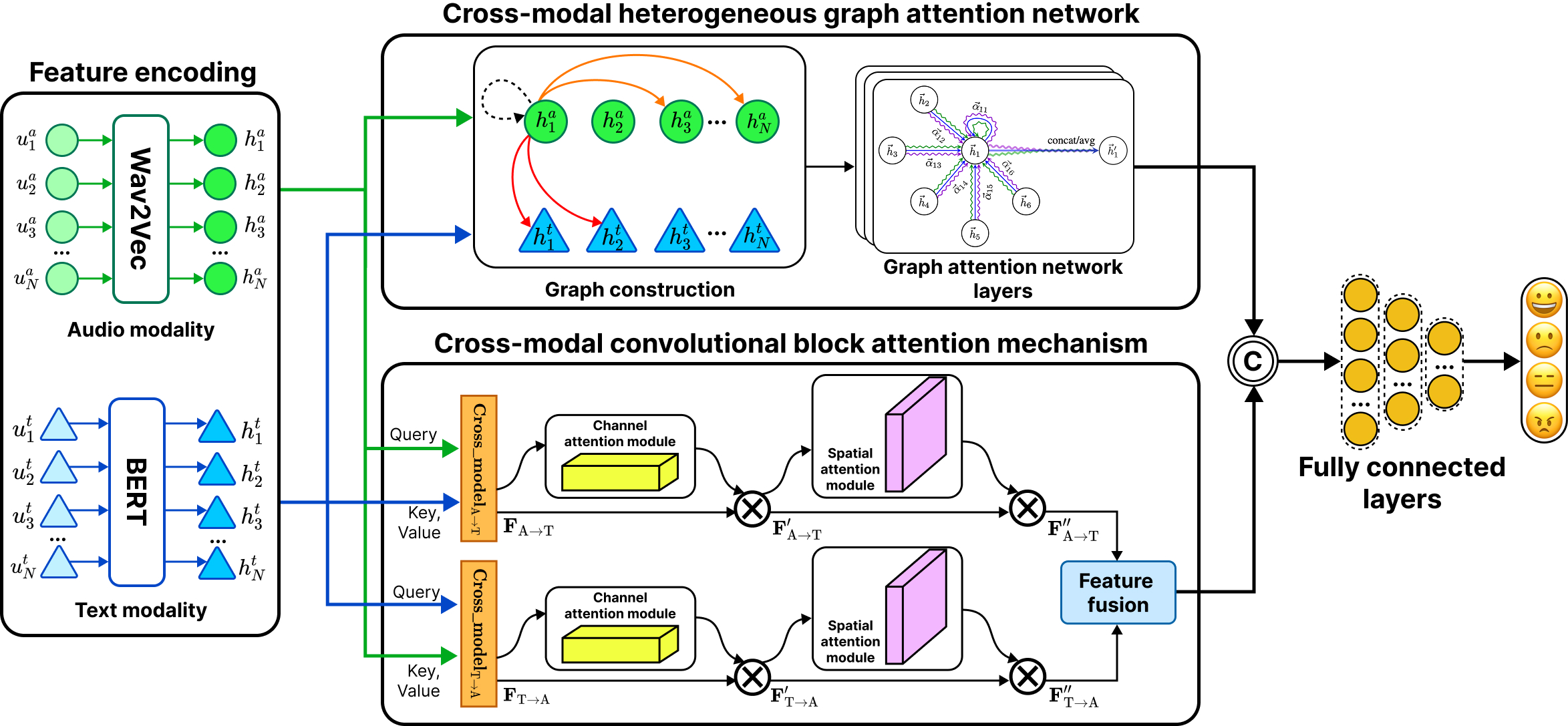
@inproceedings{Phan2025DAAL, bibtex_show = true, title = {DAAL: Dual Ambiguity in Active Learning for Object Detection with YOLOE}, author = {Phan, Duc Tai and Nguyen, Nhut Minh and Dang, Duc Ngoc Minh}, booktitle = {Proceedings of the 17th International Conference on Management of Digital Ecosystem (MEDES 2025)}, year = {2025}, month = nov, address = {Ho Chi Minh City, Vietnam}, organization = {FPT University}, note = {To appear} } - Nhut Minh Nguyen , Thu Thuy Le , Thanh Trung Nguyen, Duc Tai Phan , Anh Khoa Tran, and Duc Ngoc Minh DangIn Proceedings of the 2025 Asia-Pacific Network Operations and Management Symposium (APNOMS), Sep 2025
Multimodal Speech Emotion Recognition (SER) offers significant advantages over unimodal approaches by integrating diverse information streams such as audio and text. However, effectively fusing these heterogeneous modalities remains a significant challenge. We propose CemoBAM, a novel dualstream architecture that effectively integrates the Heterogeneous Graph Attention Network (CH-GAT) with the Cross-modal Convolutional Block Attention Mechanism (xCBAM). In CemoBAM architecture, the CH-GAT constructs a heterogeneous graph that models intra- and inter-modal relationships, employing multi-head attention to capture fine-grained dependencies across audio and text feature embeddings. The xCBAM enhances feature refinement through a cross-modal transformer with a modified 1D-CBAM, employing bidirectional cross-attention and channel-spatial attention to emphasize emotionally salient features. The CemoBAM architecture surpasses previous state-of-the-art (SOTA) methods by 0.32% on IEMOCAP and 3.25% on ESD datasets. Comprehensive ablation studies validate the impact of Top-K graph construction parameters, fusion strategies, and the complementary contributions of both modules. The results highlight CemoBAM’s robustness and potential for advancing multimodal SER applications.
@inproceedings{nguyen2025CemoBAM, bibtex_show = true, title = {CemoBAM: Advancing Multimodal Emotion Recognition through Heterogeneous Graph Networks and Cross-Modal Attention Mechanisms}, author = {Nguyen, Nhut Minh and Le, Thu Thuy and Nguyen, Thanh Trung and Phan, Duc Tai and Tran, Anh Khoa and Dang, Duc Ngoc Minh}, booktitle = {Proceedings of the 2025 Asia-Pacific Network Operations and Management Symposium (APNOMS)}, doi = {10.23919/apnoms67058.2025.11181320}, year = {2025}, month = sep, address = {Kaohsiung, Taiwan}, organization = {National Sun Yat-sen University}, } - ALMUS: Enhancing Active Learning for Object Detection with Metric-Based Uncertainty SamplingDuc Tai Phan , Nhut Minh Nguyen , Khang Phuc Nguyen , Tri Pham, and Duc Ngoc Minh DangIn Proceedings of the 2025 Asia-Pacific Network Operations and Management Symposium (APNOMS), Sep 2025
Object detection is critical in computer vision but often requires large amounts of labeled data for effective training. Active learning (AL) has emerged as a promising solution to reduce the annotation burden by selecting the most informative samples for labeling. However, existing AL methods for object detection primarily focus on uncertainty sampling, which may not effectively balance the dual challenges of classification and localization. In this study, we explore active learning for object detection, with the objective of optimizing model performance while substantially reducing the demand for annotated data. We propose a novel Active Learning with Metric-based Uncertainty Sampling (ALMUS) that works effectively for the object detection task. This approach prioritizes selecting images containing objects from categories where the model exhibits suboptimal performance, as determined by category-specific evaluation metrics. To balance the annotation budget across different object classes, we propose a dynamic allocation strategy that considers the difficulty of each class and the distribution of object instances within the dataset. This combination of strategies enables our method to effectively address the dual challenges of classification and localization in object detection tasks while still focusing on the rarest and most challenging classes. We conduct extensive experiments on the PASCAL VOC 2007 and 2012 datasets, demonstrating that our method outperforms several active learning baselines. Our results indicate that the proposed approach enhances model performance and accelerates convergence, making it a valuable contribution to the field of active learning in object detection.
@inproceedings{phan2025ALMUS, bibtex_show = true, title = {ALMUS: Enhancing Active Learning for Object Detection with Metric-Based Uncertainty Sampling}, author = {Phan, Duc Tai and Nguyen, Nhut Minh and Nguyen, Khang Phuc and Pham, Tri and Dang, Duc Ngoc Minh}, booktitle = {Proceedings of the 2025 Asia-Pacific Network Operations and Management Symposium (APNOMS)}, doi = {10.23919/apnoms67058.2025.11181447}, year = {2025}, month = sep, address = {Kaohsiung, Taiwan}, organization = {National Sun Yat-sen University}, } - YOLO-Powered Traffic Sign Detection and OpenStreetMap Integration for Intelligent NavigationDuc-Hieu Hoang , Dinh Thuan Nguyen , Quoc Huy Tran , Thanh Trung Nguyen , Nhut Minh Nguyen, and Duc Ngoc Minh DangIn Proceedings of the 2025 Asia-Pacific Network Operations and Management Symposium (APNOMS), Sep 2025
This study presents the development of a deep learning-based traffic sign recognition system integrated with OpenStreetMap (OSM) to enhance smart navigation and traffic management. The system utilizes a You Only Look Once (YOLO)based model trained on the Vietnamese Camera-based Traffic Sign Recognition 47 (VCTSR47) dataset to detect and classify Vietnamese traffic signs accurately. A dashboard camera mounted on motorbikes or cars collects real-world traffic data, automatically recognizing traffic signs, extracting Global Positioning System (GPS) coordinates, and storing relevant information in a structured database. The extracted data is integrated into OSM via Application Programming Interfaces (APIs), enabling precise visualization and real-time alerts for critical traffic signs. The system’s performance is rigorously evaluated through various metrics, including mean Average Precision (mAP), Precision, Recall, and Frames Per Second (FPS). Experimental results confirm high recognition accuracy and real-time processing efficiency, demonstrating the feasibility and potential applications of deep learning and digital mapping in modern intelligent transportation systems.
@inproceedings{hoang2025yolo, bibtex_show = true, title = {YOLO-Powered Traffic Sign Detection and OpenStreetMap Integration for Intelligent Navigation}, author = {Hoang, Duc-Hieu and Nguyen, Dinh Thuan and Tran, Quoc Huy and Nguyen, Thanh Trung and Nguyen, Nhut Minh and Dang, Duc Ngoc Minh}, doi = {10.23919/apnoms67058.2025.11181312}, booktitle = {Proceedings of the 2025 Asia-Pacific Network Operations and Management Symposium (APNOMS)}, year = {2025}, month = sep, address = {Kaohsiung, Taiwan}, organization = {National Sun Yat-sen University}, }


2024
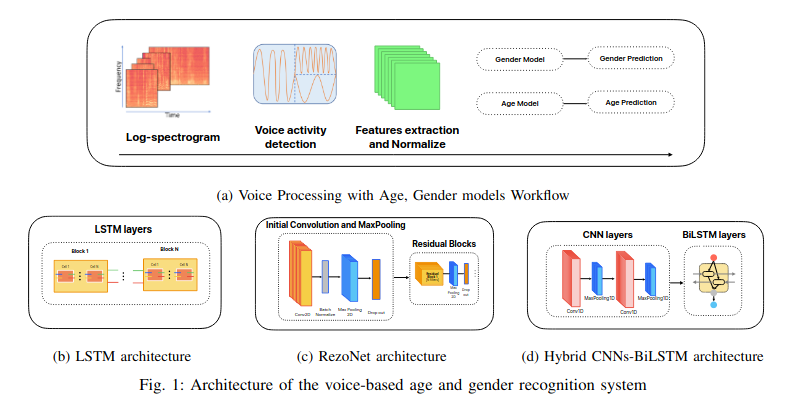
- Voice-Based Age and Gender Recognition: A Comparative Study of LSTM, RezoNet and Hybrid CNNs-BiLSTM ArchitectureNhut Minh Nguyen , Thanh Trung Nguyen , Hua Hiep Nguyen, Phuong-Nam Tran, and Duc Ngoc Minh DangIn Proceedings of the 2024 15th International Conference on Information and Communication Technology Convergence (ICTC), Sep 2024
In this study, we compared three architectures for the task of age and gender recognition from voice data: Long Short-Term Memory networks (LSTM), Hybrid of Convolutional Neural Networks and Bidirectional Long Short-Term Memory (CNNs-BiLSTM), and the recently released RezoNet architecture. The dataset used in this study was sourced from Mozilla Common Voice in Japanese. Features such as pitch, magnitude, Mel-frequency cepstral coefficients (MFCCs), and filter-bank energies were extracted from the voice data for signal processing, and the three architectures were evaluated. Our evaluation revealed that LSTM was slightly less accurate than RezoNet (83.1%), with the hybrid CNNs-BiLSTM (93.1%) and LSTM achieving the highest accuracy for gender recognition (93.5%). However, hybrid CNNs-BiLSTM architecture outperformed the other models in age recognition, achieving an accuracy of 69.75%, compared to 64.25% and 44.88% for LSTM and RezoNet, respectively. Using Japanese language data and the extracted characteristics, the hybrid CNNs-BiLSTM architecture model demonstrated the highest accuracy in both tests, highlighting its efficacy in voice-based age and gender detection. These results suggest promising avenues for future research and practical applications in this field.
@inproceedings{nguyen2024age-gender, bibtex_show = true, title = {Voice-Based Age and Gender Recognition: A Comparative Study of LSTM, RezoNet and Hybrid CNNs-BiLSTM Architecture}, author = {Nguyen, Nhut Minh and Nguyen, Thanh Trung and Nguyen, Hua Hiep and Tran, Phuong-Nam and Dang, Duc Ngoc Minh}, booktitle = {Proceedings of the 2024 15th International Conference on Information and Communication Technology Convergence (ICTC)}, pages = {1--1}, year = {2024}, publisher = {IEEE}, doi = {10.1109/ICTC62082.2024.10827387}, }